Integration with 3PAR Arrays and StoreOnce Backup Systems
As always, there is a large slew of 3PAR and StoreOnce engineering integrations within Data Protector, and this release is no exception – containing no fewer than NINE, including:
VMware incremental GRE, Power-on and Live Migrate from StoreOnce Catalyst: Data Protector users can now power-on, live migrate and perform granular recovery (i.e. recover individual files from within a virtual machine) directly from StoreOnce Catalyst that was previously exclusive to only SmartCache devices and 3PAR Snapshots.
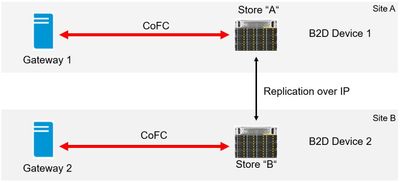
StoreOnce multi-protocol access: Backup data can now be written to a StoreOnce store by either Catalyst over IP (CoIP) or Catalyst over FC (CoFC), giving users the freedom of writing with any of those protocols while reading with another protocol, i.e. write to StoreOnce ’A‘ via CoFC, replicate to StoreOnce ‘B‘ via CoIP, and then read from StoreOnce ‘B’ via CoFC, as below.
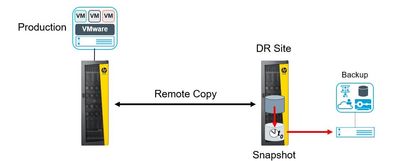
3PAR Remote Copy with VMware / Zero Downtime Backup (ZDB): With the introduction of support for 3PAR remote copy, Data Protector customers who are using ZDB with 3PAR can now take advantage of the advanced technology in both solutions allowing them to move at the storage level their VM snapshots to a secondary array at a DR site, where all of the backup operations can be undertaken without any I/O interruption to the production systems on the production array.
3PAR Port Set/Host Set/Volume Set Support: When working with 3PAR, Data Protector 9.07 sees the introduction of support for Host, Port and Volume Sets. The creation of sets of Hosts, Ports and Volumes makes it much easier when working with complex configurations and is in-line with HPE StoreServ 3PAR best practices.
3PAR Peer Persistence: Peer Persistence makes sure that if 3PAR resources change (paths, ports, array controller, etc) that resource presentation towards server hosts is managed properly.
With Data Protector 9.07, we are continuing to deliver on our commitment to simplify management and add more value to customers that use Data Protector with HPE Storage systems
Enhancements for Virtualized Environments
In Data Protector 9.07 we have also introduced new features for Microsoft Hyper-V and VMware environments:
VMware non-CBT is back: Due to popular demand and also to stay compatible with older VMware systems the Change Block Tracking options are back to be set manually per VM or common selected VM‘s
Individual VHD/VHDX support for Microsoft Hyper-V: Currently in Data Protector 9.06 and earlier versions, Hyper-V virtual machines are backed up as one object, however for restore purposes administrators may want to choose individual virtual disks to be restored from a given VM instead of all virtual disks. With Data Protector 9.07, that problem is solved with the introduction of support for individual .VHD and .VHDX virtual hard disks. We also offer the merging of snapshots for a clean environment after a restore by removing unwanted snapshots that were left in the system.
OpenStack Support
Data Protector 9.07 introduces the support for OpenStack Cinder Volume backups via VMware. Data Protector can now make use of various major components in OpenStack:
SWIFT, which is used mainly as backup target. Supported with previous versions of Data Protector as a backup device type.
CINDER, which can be a source device for backups. This is where Cloud VM‘s store their data during runtime.
NOVA is a compute instance where CINDER volumes are mapped to. The Nova Instance is seen as a VM in VMware, whereas the Cinder volume appears as a Shadow VM under the Nova Instance VM.
Data Protectors supports VMware as the hypervisor for OpenStack Cloud VM‘s where users can backup and restore VMs residing in NOVA or Shadow VMs providing improved integration with OpenStack environments.
In a restore situation Data Protector can bring back the VM on VMware as well as the NOVA instance and CINDER volumes attached to it in the cloud. DP can also register these resources into the OpenStack dashboard. We are very excited about this new feature!
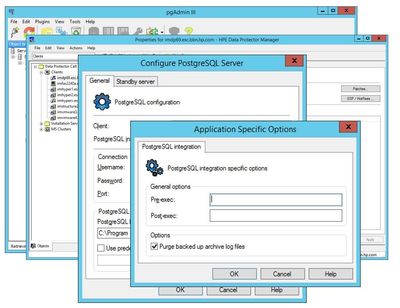
PostgreSQL Support
We are adding the support for the backup and recovery of PostgreSQL Enterprise DB databases via the ‘online integration agents’ family, allowing all-encompassing data protection and point-in-time database recovery for all users of PostgreSQL / EnterpriseDB.
This recent addition increases our database backup support to a very comprehensive list including Oracle, MySQL, Microsoft SQL Server, PostgreSQL and more. For detailed information please see the support matrices and integration guides.
NetApp Integration Enhancements
And for the NetApp customers, we are very excited to announce a range of Data Protector integration enhancements, including 3-way NDMP backup and NetApp NDMP Cluster Aware Backup.
A large number of NetApp systems are run in clustered mode which gives the ability for NDMP to fail over to another node or to make use of its resources.
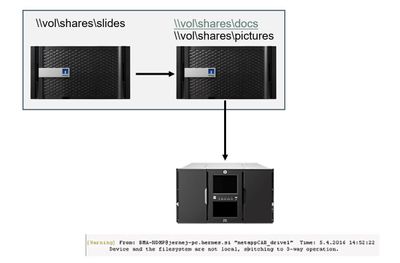
This is why we have introduced an agent to take care of Cluster Aware Backups (CAB), which removes the management overhead from backup/recovery configuration and usage. To use Cluster Aware Backups with NetApp, simply choose ‘NDMP – NetApp CAB’ when adding a new device.
In the example above, a backup is configured for volumes \docs, \pictures and \slides. Volumes are spread over both cluster nodes in this example and the backup device is connected to the right host. Data Protector switches to 3-way backup mode reading the “\slides“ volume from the left node via the right node. In the scenario, Data Protector and Cluster Aware Backup will also take care of the changes (i.e. failover) regarding resources and act appropriately.